朋友問了一個奇妙的狀況,下面這個 Spring JPA 的 NativeQuery 回傳的 column name 應該是 as 之後的名稱 (以下為測試的 NativeQuery,非朋友實際執行的 SQL):
String sql = "select Name as Name, SeqNo as SeqNo from Test where Name = :name";
List<Tuple> result = entityManager.createNativeQuery(sql, Tuple.class).setParameter("name", name)
.getResultList();
return result;
也就是 Name 和 SeqNo,但跑出來的結果卻是全大寫的 NAME 和 SEQNO:
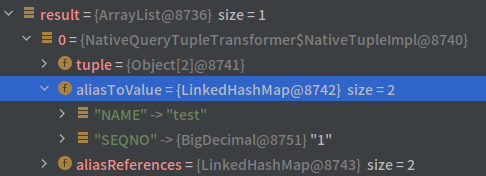
而且我使用 SQLServer 測試時無法重現這個狀況。一開始以為是不是 Spring JPA 的設定問題,但 Google 大神沒有降什麼神旨,翻了 Spring JPA 的文件也沒看到什麼相關的設定,想說只好用 debug 模式來追蹤一下到底執行過程中是不是有什麼地方會去修改 alias column name。 在追蹤的過程中,突然看到這行:
 雖然和執行過程無關 😅,但
雖然和執行過程無關 😅,但 factory.getJdbcServices().getDialect() 讓我想到朋友用的是 H2 Database,馬上去官網查了一下發現果然是因為 H2 預設對於沒有使用 "" 括起來的欄位名稱都會依設定轉成全大寫或全小寫:
Name
With default settings unquoted names are converted to upper case. There is no maximum name length.
Identifiers in H2 are case sensitive by default. Because unquoted names are converted to upper case, they can be written in any case anyway. When both quoted and unquoted names are used for the same identifier the quoted names must be written in upper case. Identifiers with lowercase characters can be written only as a quoted name, they aren’t accessible with unquoted names.
If
DATABASE_TO_UPPERsetting is set toFALSEthe unquoted names aren’t converted to upper case.If
DATABASE_TO_LOWERsetting is set toTRUEthe unquoted names are converted to lower case instead.If
CASE_INSENSITIVE_IDENTIFIERSsetting is set toTRUEall identifiers are case insensitive.
所以如果要保持 SQL 中的大小寫必須用 "" 括起來:
Quoted Name
|
" anything "|Case of characters in quoted names is preserved as is. Such names can contain spaces. There is no maximum name length. Two double quotes can be used to create a single double quote inside an identifier. With default settings identifiers in H2 are case sensitive.
Example:
“FirstName”
因此如果上面的 NativeQuery 改寫成:
String sql = "select Name as \"Name\", SeqNo as \"SeqNo\" from Test where Name = :name";
List<Tuple> result = entityManager.createNativeQuery(sql, Tuple.class).setParameter("name", name)
.getResultList();
return result;
就可以正常回傳 Name 和 SeqNo:
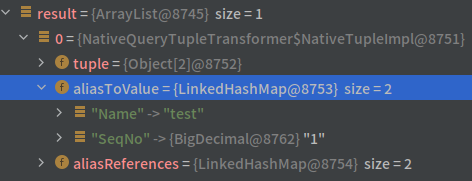
其實這件事也讓我在思考,使用像 H2 這樣的 Memory Database 雖然可以加速測試,但畢竟它和正式線上的資料庫不同,這樣的話這些測試是否能真實反映出實際的狀況呢?或者在 Unit Test 時直接使用如 DBUnit 這類的模擬假資料,反正使用 H2 模擬的也一樣只是假資料,而在 Integration Test 時使用和正式環境相同的資料庫這樣才更有意義也不一定?
如果有什麼想法或需要指正的地方,歡迎您留言或來信 😄